import pandas as pdLab 00: Football Fourth Down Decisions
For Lab 00, you will use (American) football data to develop a model that will assist with in-game decision making.
Background
American football is a team sport played between two teams of eleven players each on a rectangular field with an “end zone” at each end. The game is divided into four quarters, with the objective of advancing the ball into the opponent’s end zone to score points via a touchdown or field goal.
Play is organized into discrete segments called “downs,” with each team given four attempts (downs) to advance the ball at least ten yards. If successful, they are awarded a new set of downs. If they fail, possession of the ball is given to the opposing team. Each down begins with a “snap” from the center, and the team with the ball (offense) attempts to advance while the other team (defense) tries to prevent them from doing so. The game emphasizes strategy, with each play being a carefully planned and executed attempt to gain yards or disrupt the opponent’s progress.
“Going for it on fourth down” involves a high-risk gamble where a team opts to attempt to advance the ball rather than punting or kicking a field goal. Success grants a new set of downs and a chance to score, but failure hands over possession to the opponent (a turnover) with favorable field position, potentially leading to a quick score. This decision can shift game momentum and is influenced by factors like field position and game context.
In recent history, more and more teams are being aggressive and choosing to take risks on fourth down.
Specifically, in a fourth down situation, the offensive coordinator, a coach that specializes in real-time game decisions for the offense, often called play calling, has three choices:
- Punt
- Punting is in some sense a surrender, giving up, and purposefully giving possession to the opposing team. However, this can be strategically advantageous because if successful, it will place the opposing team far from the end zone, significancy reducing their changes of scoring.
- Kick a field goal
- Kicking a field goal is a low-risk, low-reward proposition. With favorable field position, kicking a field goal provides a high probability of scoring some points (three) but forfeits the chance to score a touchdown (at least six points).
- Go for it
- “Going for it” on fourth down is a risky decision that uses the last of the four downs in an attempt to move the ball the remaining yards need to achieve a first down (retaining the ability to score a touchdown) or simply score a touchdown. Should the offense not advance the ball the required number of yards, they turnover the ball to the opposing team, in a much better position than had they punted.
The game situation, including the field position, time remaining, and score, are all considered when making decisions like this.
For much of football history, decisions such as these were largely made by gut instinct. In the modern game, football organizations employ data science teams that use data to inform in-game decisions. Here’s an example job posting at the time of writing this lab:
These teams of data scientists are always attempting to do one thing: help the team win.
Modern NFL teams are likely to have a sophisticated win probability model that evaluates and guides each in-game decision, expressed as the effect on the probability to win the game. In this lab, you will develop a model that assesses the risk-reward of “going for it” on fourth down.
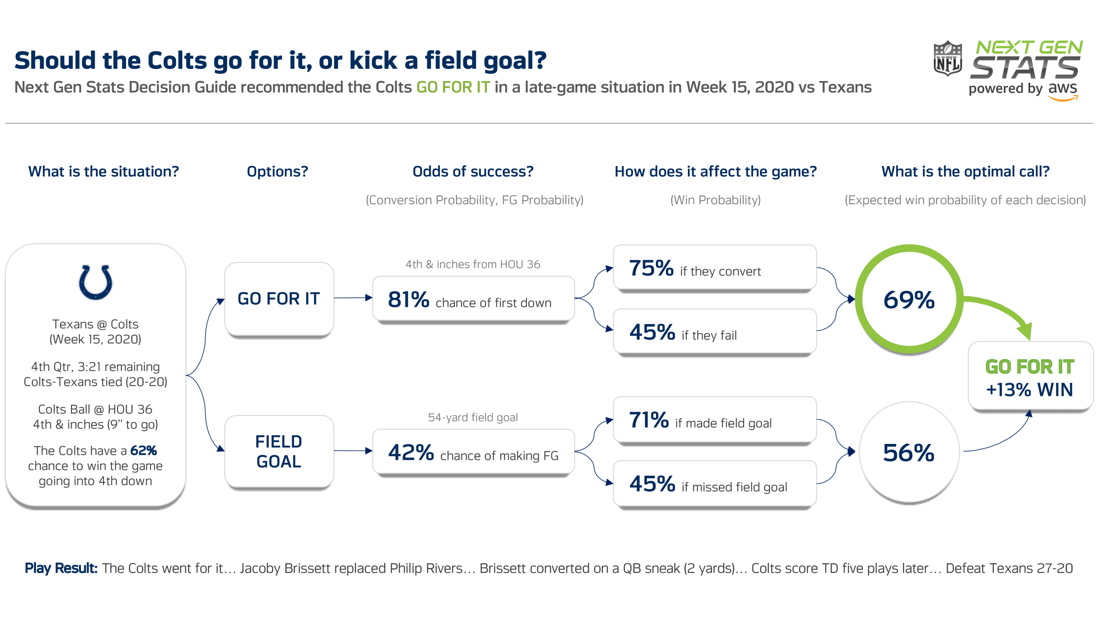
The above diagram, from an article on using so-called “next-gen” statistics to inform games decision such as attempting to convert on fourth-down, shows potential decisions (and importantly their estimated probabilities) that affect an NFL team’s probability of winning a game given the game situation. This illustrates that individual models, like a model to predict converting on fourth down, are part of a larger system, which gives context.
Additional information:
Scenario and Goal
You work for an NFL team as an analyst. You are tasked with creating a model that estimates the probability that an attempt to convert a fourth down is successful, given game-state information such as yards-to-go, yards-to-goal, and the type of play (run or pass) considered. This model will be used within a larger system that allows the offensive coordinator to evaluate play-calling decisions and how they effect the overall probability of winning the game.
Data
To achieve the goal of this lab, we will need data about many previous fourth-down attempts in the NFL. The necessary data is provided in the following two files:
Source
The data used in this lab was acquired using the nfl_data_py package. This package sources data from the nflverse-data repository. The nfl_data_py package has an R analog, nflreadr, which contains a searchable data dictionary as a part of its documentation for play-by-play data.
The acquired play-by-play data was heavily pre-processed for this lab. Importantly, the full play-by-play data was subset to only fourth-down conversion attempts, that is, a run or a pass on fourth down.
Data Dictionary
- The train data contains one row per fourth-down conversion attempt in the 2019, 2020, and 2021 NFL seasons.
- The test data contains one row per fourth-down conversion attempt in the 2022 NFL season.
- The (hidden) production data contains one row per fourth-down conversion attempt in the 2023 NFL season.
Response
converted
[category]Result of fourth-down conversion attempt. One of['No', 'Yes'].
Features
togo
[float64]Distance in yards from either the first down marker or the end zone in goal down situations. Distance needed to successfully convert the fourth-down attempt.
yardline
[float64]Distance in yards from the opponent’s end zone. Distance needed to score a touchdown.
play_type
[category]Type of play. One of['Pass', 'Run']. Pass plays include sacks. Run plays includes scrambles.
Data in Python
To load the data in Python, use:
football_train = pd.read_parquet("https://cs307.org/lab-00/data/football-train.parquet")
football_test = pd.read_parquet("https://cs307.org/lab-00/data/football-test.parquet")Prepare Data for Machine Learning
Create the X and y variants of the data for use with sklearn:
# create X and y for train
X_train = football_train.drop(columns=["converted"])
X_train = pd.get_dummies(X_train, dtype=float, drop_first=True)
y_train = football_train["converted"]
# create X and y for test
X_test = football_test.drop(columns=["converted"])
X_test = pd.get_dummies(X_test, dtype=float, drop_first=True)
y_test = football_test["converted"]You can assume that within the autograder, similar processing is performed on the production data.
Sample Statistics
Before modeling, be sure to look at the data. Calculate the summary statistics requested on PrairieLearn and create a visualization for your report.
Models
For this lab you will select one model to submit to the autograder. You may use any modeling techniques you’d like. The only rules are:
- Models must start from the given training data, unmodified.
- Importantly, the types and shapes of
X_trainandy_trainshould not be changed. - In the autograder, we will call
mod.predict(X_test)on your model, where your model is loaded asmodandX_testhas a compatible shape with and the same variable names and types asX_train. - In the autograder, we will call
mod.predict(X_prod)on your model, where your model is loaded asmodandX_prodhas a compatible shape with and the same variable names and types asX_train.
- Importantly, the types and shapes of
- Your model must have a
fitmethod. - Your model must have a
predictmethod. - Your model must have a
predict_probamethod. - Your model should be created with
scikit-learnversion1.5.1or newer. - Your model should be serialized with
joblibversion1.4.2or newer.- Your serialized model must be less than 5MB.
To obtain the maximum points via the autograder, your model performance must meet or exceed:
Test Accuracy: 0.57
Production Accuracy: 0.62Model Persistence
To save your model for submission to the autograder, use the dump function from the joblib library. Check PrairieLearn for the filename that the autograder expects for this lab.
from joblib import dump
dump(mod, "filename.joblib")Discussion
As always, be sure to state a conclusion, that is, whether or not you would use the model you trained and selected for the real world scenario described at the start of the lab! Justify your conclusion. If you trained multiple models that are mentioned in your report, first make clear which model you selected and are considering for use in practice.
Additional discussion prompts:
- Noting how the data was split, do you believe this model would have similar performance if used in 2024?
- In this lab, we evaluated the models solely based on accuracy. Given the scenario, is that acceptable?
- Any potential issues with this model? Or, how could this model be improved?
When answering discussion prompts: Do not simply answer the prompt! Answer the prompt, but write as if the prompt did not exist. Write your report as if the person reading it did not have access to this document!
Template Notebook
Submission
On Canvas, be sure to submit both your source .ipynb file and a rendered .html version of the report.